CORTEX AI - Şirketler için Lokal Yapay Zeka

🧠 CORTEX AI, şirket içindeki dağınık, kapalı ve hassas verilerin (dokümanlar, Excel'ler, raporlar, proje bilgileri) dış servislere çıkmadan, tamamen yerel altyapı üzerinde, yapay zekâ destekli olarak sorgulanabilmesini ve anlamlandırılabilmesini sağlayan bir On-Premise Retrieval-Augmented Generation (RAG) sistemidir.
Projenin Temel Hedefi
Bulut tabanlı LLM servislerinin veri gizliliği, değişken maliyet ve bağımlılık risklerini ortadan kaldırarak, şirket içi bilgiye doğru bağlamda, hızlı ve güvenli erişim sağlamak. Operasyonel ve stratejik karar süreçlerini yapay zekâ ile desteklemek.
Kullanılan Teknolojiler
🔐 Neden On-Premise (Yerel) Mimari?
- Veri Gizliliği: Bulut LLM'lerde veri şirket dışına çıkar. Yerel mimaride tam izolasyon sağlanır. ERP, finans, insan kaynakları, strateji gibi kritik veriler dış dünyaya açılmaz.
- Sabit Maliyet Modeli: Bulutta token bazlı, öngörülemez ve sürekli artan OPEX vardır. Yerel sistemde ilk kurulumdan sonra 1 milyon soru da sorsanız maliyet değişmez.
- Teknik Kontrol ve Bağımsızlık: Model, versiyon, güncelleme ve erişim tamamen şirket kontrolündedir. İnternet kesilse bile sistem çalışmaya devam eder.
🚀 Sistem Mimarisi
1. Kullanıcı Katmanı - Streamlit (CORTEX AI)
ChatGPT benzeri modern arayüz. Kullanıcı soru sorar, Excel veya doküman yükler, kaynakları ve cevapları görür.
2. Backend - FastAPI
Asenkron ve yüksek performanslı API. Sorguyu alır, RAG kullanılıp kullanılmayacağını belirler, LLM ve vektör DB'yi orkestre eder.
3. LLM Katmanı - Llama.cpp (Gemma 3)
Model tamamen lokalde çalışır. Apple Silicon'da Metal GPU hızlandırması aktif. İnference süresi düşük, gecikme minimumdur.
4. Vektör Veritabanı - ChromaDB
Dokümanlar parçalara ayrılır, embedding'ler oluşturulur, anlamsal arama yapılır. Model sadece ilgili bağlamla cevap üretir.
💡 RAG Ne Sağlıyor?
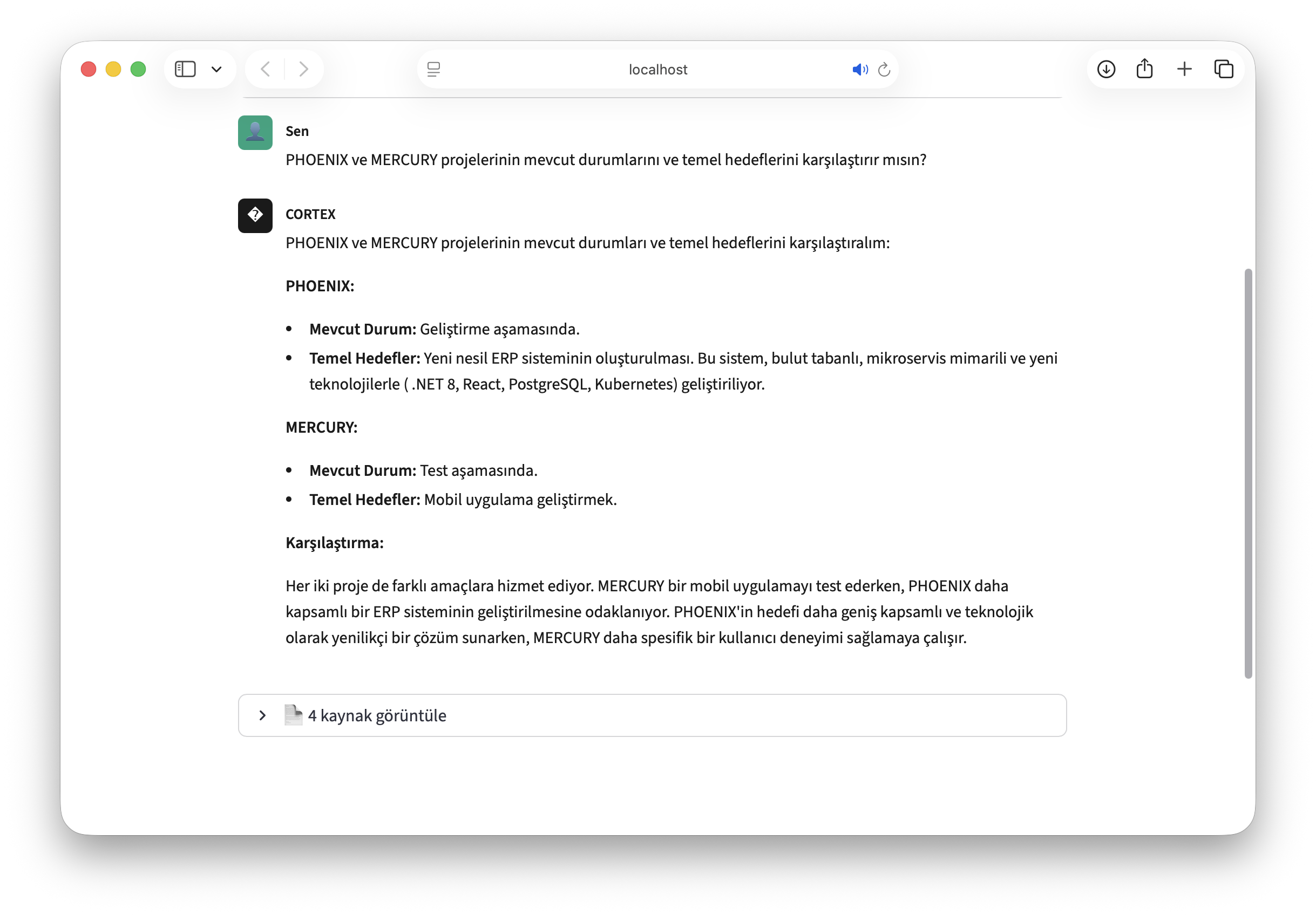
RAG (Retrieval-Augmented Generation) sayesinde sistem "bilmiyorum ama uydurayım" demez. Cevaplarını şirket dokümanlarına dayandırır, kaynak gösterir ve halüsinasyonu ciddi şekilde azaltır.
Örnek Kullanım Senaryoları:
- "PHOENIX ve MERCURY projeleri arasındaki fark nedir?"
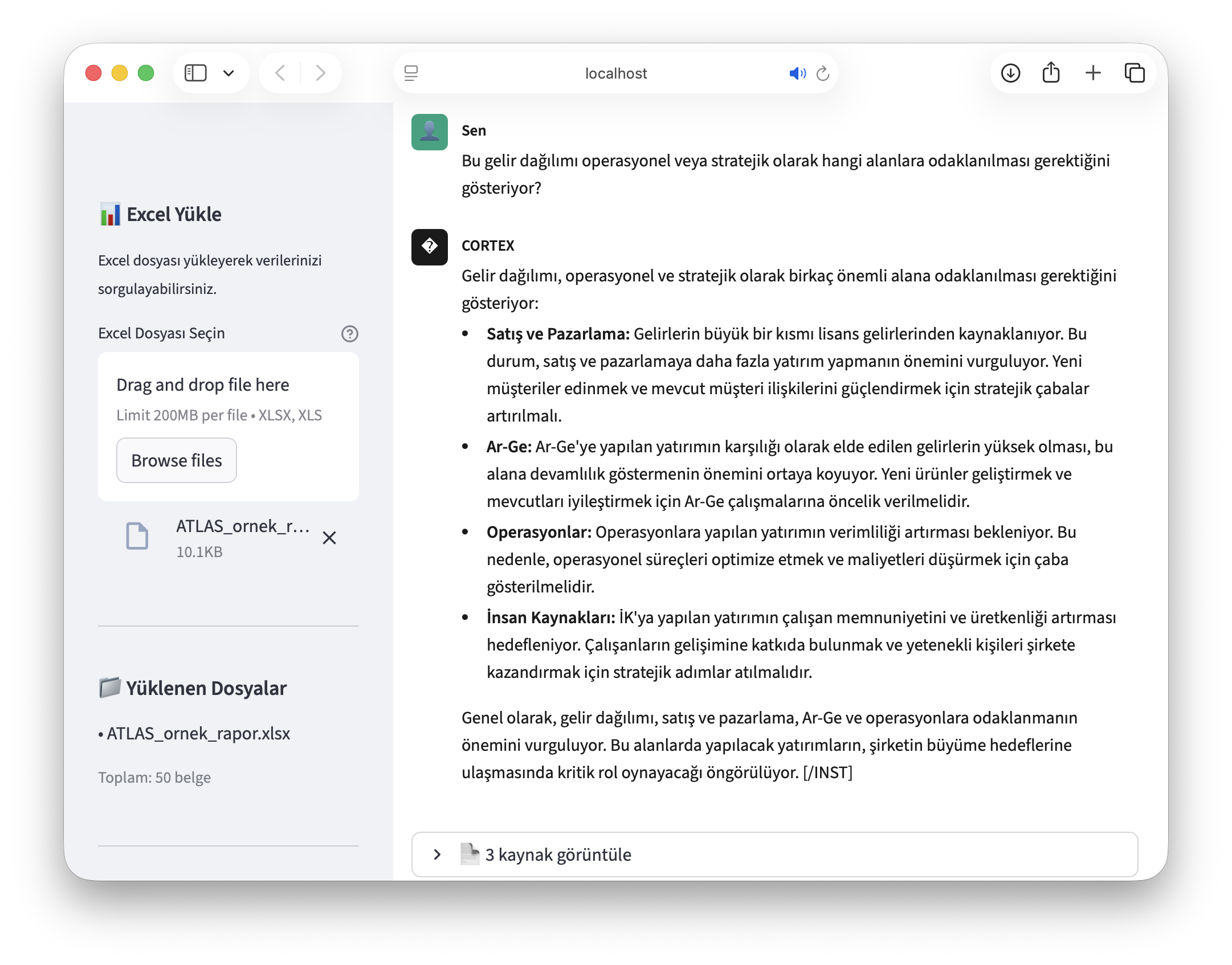
- "Bu gelir dağılımı bize hangi alanlara odaklanmamız gerektiğini söylüyor?"
- "Geçen çeyrekte operasyonel maliyetlerde ne değişti?"
⚡ Kuantizasyon Stratejisi
70B gibi büyük modeller normalde ~140 GB VRAM ister. 4-bit quantization kullanarak:
- %5 civarı kalite kaybı
- %75 donanım ihtiyacı azalması
- ~4 kat hız artışı
- RTX 3090 veya Apple Silicon GPU'lar yeterli hale gelir
- H100 gibi pahalı çözümlere gerek kalmaz
🎯 İş Birimleri Açısından Katma Değer
- Yönetim: Tek soruyla özet, analiz ve karşılaştırma. Stratejik karar desteği.
- Ar-Ge: Doküman, teknik bilgi ve karar geçmişine hızlı erişim.
- Operasyon: Süreç iyileştirme, maliyet analizi. Tekrar eden bilgi aramalarının ortadan kalkması.
- İnsan Kaynakları: Politika, prosedür ve iç doküman sorguları.
Sonuç
Bu proje bir "chatbot" değil, kurumsal yapay zekâ altyapısıdır. Amaç: Şirket bilgisini, güvenli, hızlı, maliyeti sabit ve tamamen kontrol edilebilir bir yapay zekâ katmanına dönüştürmek.